CAP Theorem: What It Actually Means for the Systems You Build
CAP theorem is one of those concepts that gets brought up in every system design interview and architectural review — but is often reduced to a single sentence: "you can only have two of the three." That framing is technically accurate and practically misleading at the same time.
If you're designing distributed systems for a living, you need a sharper mental model than the triangle. This post is about building that model.
The Theorem, Precisely
Eric Brewer proposed CAP in 2000. Gilbert and Lynch formally proved it in 2002. It states that a distributed data store can guarantee at most two of these three properties simultaneously:

What Each Property Actually Means
Consistency (C)
Every read receives the most recent write — or an error. Not to be confused with the C in ACID (which is about invariants). CAP's consistency is linearisability: the system behaves as if there's a single, up-to-date copy of the data. If you write to node A, any subsequent read from node B must reflect that write.
Availability (A)
Every request receives a non-error response — though it may not contain the most recent data. Note: availability in the CAP sense is absolute. A system that responds slowly is still available. A system that returns an error because it can't reach a quorum is not.
Partition Tolerance (P)
The system continues operating even when network partitions occur — i.e., when nodes cannot communicate with each other. This is the property you cannot opt out of in any real distributed system. Networks fail. Packets get dropped. The partition will happen.
The real choice is CP vs AP. CA systems exist only as single-node databases (like a standalone PostgreSQL instance). The moment you replicate across nodes, you must decide: when a partition occurs, do you sacrifice consistency or availability?
When a Partition Happens: The Fork in the Road
Here's the scenario you're always designing for: Emma confirms an order on the Europe server, but the replication link to the USA server is broken. Anna then reads the same order from the USA server. What does the system do?
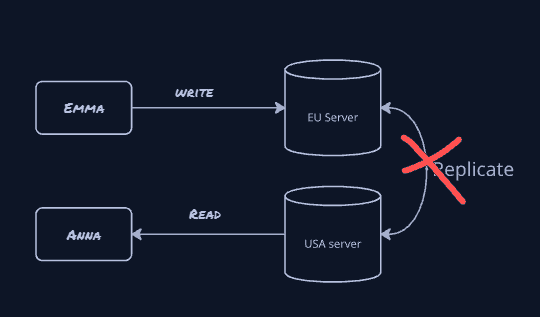
CP vs AP: The Real Tradeoffs
| Property | CP Consistent + Partition-tolerant | AP Available + Partition-tolerant |
|---|---|---|
| During partition | Rejects operations that cannot be completed consistently; may become read-only or unavailable on one side | Continues serving requests on both sides as much as possible; replicas may diverge |
| After healing | Replicas catch up from the authoritative history; usually no conflict reconciliation between independently accepted writes | Conflicting or concurrent updates may need reconciliation (last-write-wins, merge rules, CRDTs, manual resolution) |
| Latency | Often higher for strong writes and strong reads because coordination/quorum is needed | Often lower for local operations because coordination can be deferred |
| Examples | ZooKeeper, etcd, HBase | Cassandra, CouchDB, Riak, Dynamo-style systems |
| Good for | Leader election, coordination, strongly consistent metadata, financial core records | Shopping carts, feeds, analytics, DNS-like workloads, eventually consistent state |
Pick the Right Model for the Domain
The choice isn't one-size-fits-all, and modern systems often mix both within the same product. Here's how to think about it by domain:
Order Management / Inventory
Two nodes must never disagree on whether an order was confirmed or stock was reserved. Reject the write if quorum is not reached. Availability is the sacrifice.
Shopping Cart
Amazon famously chose AP for carts. A user adding an item during a partition is better than an error page. Reconcile duplicates at checkout.
Distributed Locks / Leader Election
Two nodes must never both think they hold the lock. ZooKeeper and etcd are purpose-built for this — consistency is non-negotiable.
Social Media Feed / Likes
Showing a slightly stale like count is fine. Returning a 503 to a user scrolling their feed is not. Eventual consistency is the right call.
Config / Feature Flags
Half your fleet seeing an old flag state and half seeing the new one can cause serious inconsistencies. You'd rather block the rollout than have nodes diverge on which features are active.
DNS / Config
DNS propagation can be stale by minutes. That's an explicit AP tradeoff — availability and partition tolerance trump serving the latest record.
Beyond CAP: PACELC
CAP has a known limitation: it only reasons about behaviour during a partition. But partitions are rare. What about normal operation?
Daniel Abadi's PACELC model extends CAP to cover this:
The model reads as: if there is a Partition, choose between Availability and Consistency; Else (during normal operation), choose between Latency and Consistency. DynamoDB and Cassandra land in PA/EL — available during partitions, low-latency in normal operation. BigTable and MongoDB are PC/EC — consistent in both cases, at the cost of latency and availability under partition.
In practice, most engineers care more about the EC half day-to-day.
Cassandra's tunable consistency — where you can set QUORUM,
ONE, or ALL per read/write — is exactly this tradeoff
being exposed as a dial.
What This Means When You're Designing a System
The questions I ask when choosing a data store or designing replication strategy:
- What's worse: stale data or an error? If a one-second-old read causes real harm, you need CP. If an error page causes more harm than slightly outdated data, lean AP.
- Can you handle conflict resolution? AP systems push conflict resolution to you. Last-write-wins loses data. CRDTs are elegant but complex. Know your strategy before committing.
- Are partitions realistic in your setup? A single-region deployment with reliable networking rarely partitions. But multi-region or multi-AZ? Design for it explicitly.
Once you've answered those questions, the choice shapes your design concretely:
- Implement distributed transactions
- Limit writes to a single leader
- Use consensus protocols (Raft, Paxos)
- Accept higher latency as the cost
- Use multiple replicas, write locally
- CDC and eventual consistency as first-class citizens
- Idempotency keys on every operation
- Design a reconciliation strategy upfront
The common mistake: choosing a CP-leaning system for an availability-first use case, which adds unnecessary coordination latency and failure sensitivity, or choosing an AP-leaning system for a correctness-critical use case, then trying to patch over the consistency gaps in application code. That usually ends badly
How This Shows Up in Code
CAP tradeoffs are usually visible in operation design, not in database labels — regardless of language or framework. The question isn't "which DB is CP?" — it's how each operation in your service behaves under partition. A CP-leaning operation fails fast when it can't guarantee freshness. An AP-leaning operation accepts locally and converges later.
// CP-leaning: fail rather than return possibly stale data
// Require quorum before serving the response
if (!clusterCoordinator.hasQuorum()) {
throw new ResponseStatusException(
HttpStatus.SERVICE_UNAVAILABLE,
"Cannot guarantee consistent result"
);
}
// AP-leaning: accept now, converge later
// Write locally, replicate async — caller gets immediate success
orderEventStore.appendLocally(event);
eventBus.publishAsync(event);In practice this means annotating or documenting operations explicitly: this endpoint requires quorum, this write is fire-and-forget with idempotency key. That discipline pays off fast when you're debugging an incident at 2 AM.
The Honest Summary
CAP theorem doesn't tell you what to build — it tells you what you're giving up. The triangle isn't a constraint to fight; it's a framework for having an honest conversation with your team about what your system actually needs to guarantee.
The natural next question after CAP is consistency models — eventual, strong, causal — and how specific databases actually implement them. I'll write that up next. If there's a particular angle you'd like covered, reach out at longin.koziolkiewicz@gmail.com.